
https://arxiv.org/abs/2310.10404
Introduction
画像からお互いの関係を抽出したScege Graph生成はCVで重要な道具。これを生成する手法は基本的にfully-supervisedで訓練されないといけなかった。そこで、Weakly-Supervised Scene Graph Generationという需要が高まる。現在の主なアイディアは「画像のキャプションとその画像を使って学習をするもの」。(キャプションでの説明の部分の一部だけラベル付けされていると言える)
具体的な流れでは、
- 画像とキャプションを集める。
- キャプションを「主語」、「述語」、「動詞」に分割。
- 2で分割したものを、同義語/上位語/下位語の関係を利用して(Knowledge Baseなどで)作り上げる。ここで、KBでその単語が存在しないことが理由で変換できず「主語」「述語」「動詞」のいずれかが欠けてしまっているとき、Scene Graphには追加しない。
- 3で正規化をしたものを、物体検知のネットで見つけたものと照合する。
現行のWSSGGはステップ4が主流。
だが、先行研究ではステップ2と3において以下の問題を抱えている。
- 意味の過度の簡易化。
- 例として、lying onという関係が単純にonに変換されていたり。
- 本来存在するより複雑な関係は出現頻度0だとされてしまって、生成する際に出てこなくなってしまう。
- 生成される、低密度すぎるSG。
- ステップ3での太字の問題。elephant carry log. というもので、logというものが存在しないので、述語が欠けてこの関係がScene Graphに追加できない。
多分やりたいことは、lying on → onになってしまう問題やlogがわからない問題を、LLMの言語について強力な言い換え能力を用いることによって、解決すること。
Chain of Thoughtの概念を使うことによって、2つのステップに分割する。ステップ2での分割作業と、ステップ3でのKBを使った言いかえを代替する。
Related Work
既存のWSSGG
VSPNetは、未配置の三つ組と画像領域の間の工事関係を反映する反復グラフ整合アルゴリズムがあるらしい。
SGNLSでは、事前に訓練済の資格言語モデルを使うらしい。
VS3は、未配置の三つ組みの実態テキストと画像領域の間の類似性を計算し、未配置の三つ組から配置していく。
だけど、前述のように過度な単純化とScene Graphの薄い中身問題となる。
Method
Problem Formulation
Scene Graphの定義は となる。sは主語、oは目的語、pは動詞。
WSSGGでは、キャプションからそれを生成している。
Prompt Configuration
- Chain1: キャプションから3つ組を抽出。
- Chain2: 単語の言いかえを行う。
Chat GPTに渡すPromptは、「タスクの説明」、「問答例」、「実際の質問」とin context few-shot learningの典型例。
Chain1: キャプションから3つ組の抽出。
(Task Description)
FROM THE GIVEN SENTENCE, THE TASK IS TO EXTRACT MEANINGFUL TRIPLETS FORMED AS ⟨SUBJECT, PREDICATE, OBJECT⟩
(In-context Example. Repeat Many Times)
Four clocks sitting on a floor next to a woman’s feet
(Question)
Q. Given the sentence “A surfer on rock holdin wooden surfboard,” paraphrase the sentence and extract meaningful triplets.Chain2: LLMによる、単語の言いかえ
既存の定義されている単語リストに、今ある単語がない場合言い換えてもらう。(pegion → bird,
surfboards → surfboardのように)
GIVEN THE LEXEME {ENTITY}, FIND SEMANTICALLY RELEVANT LEXEME IN THE PREDEFINED ENTITY LEXICON
(In-context Example)
(Question)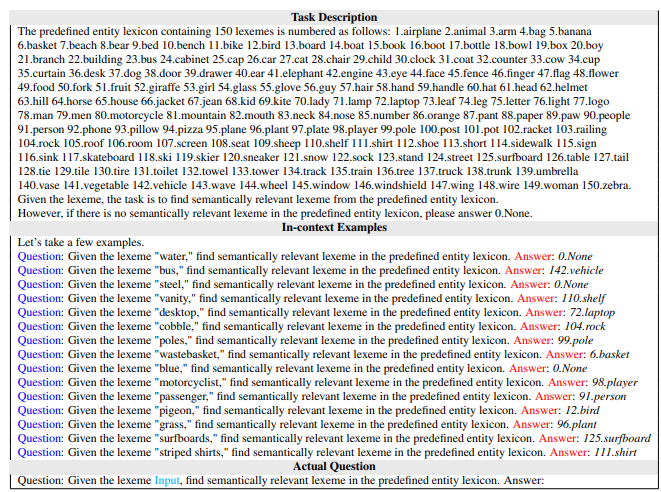
動詞の言い換え例↓

その言いかえを持っても、主語述語動詞のうち1つはNoneになってしまったら、捨てる。
思索: 主語述語だけわかっていればそれでも学習してよくね?